Každý dobře fungující psychologický dotazník je výsledkem poměrně náročného aplikovaného výzkumu. Je nutné zkombinovat hluboké odborné znalosti o tom, co chceme zjišťovat (v našem případě tedy např. dyslexie, úzkosti a podobně), a psychometrické dovednosti (tzn. dovednosti související s vývojem psychodiagnostických metod). Celý proces je značně zdlouhavý a nákladný, a proto řada podobně vypadajících služeb některé kroky přeskakuje či zjednodušuje. To má ovšem značný negativní efekt na kvalitu výsledného dotazníku. Bohužel, běžný uživatel služby nedokáže zpravidla kvalitu diagnostické metody posoudit pouze z vlastní zkušenosti. Příčin je více – například závěry testů a dotazníků jsou jen pravděpodobnostní, a z jediného výsledku, který máte k dispozici, na systematický vzorec nelze usuzovat. Zároveň různé „podvodné“ dotazníky (podobně jako astrologové nebo léčitelé) využívají ve svých zprávách obecná, nepříliš určitá tvrzení, která platí o většině lidí, a která tak zní uživateli metody věrohodně (tzv. Forerův efekt).
Abychom ukázali, že jsme k vývoji služby ePsycholog přistupovali opravdu s maximální důsledností a odborností, jsou veškeré kroky podrobně popsány v našem psychometrickém manuálu tak, jak bývá zvykem u jiných psychodiagnostických metod. Tento dokument je ovšem psaný primárně pro odborníky, běžnému čtenáři bez dostatečných psychometrických znalostí nebude příliš srozumitelný. Proto vám, rodičům, nabízíme i tento zjednodušený text.
Tvorba obsahu
Samotná tvorba obsahu a struktury dotazníku probíhala v několika krocích od roku 2017. Po vytipování klíčových oblastí (např. ADHD, úzkosti) byla každá z nich pečlivě definovaná a vymezená – jednoznačně jsme stanovili okruhy symptomů (projevů psychických potíží), které by měly být součástí dotazníku. Poté jsme začali připravovat tzv. položky (otázky v dotazníku). V tomto kroku hráli zásadní roli naši odborní garanti , kteří měli jako odborníci s mnohaletou zkušeností přímo z praxe vždy poslední slovo. Tímto způsobem vzniklo 470 unikátních položek zaměřených na různé symptomy. Celý postup byl výrazně složitější a obsahoval různé opakující se kroky, kterými jsme se snažili zajistit tzv. obsahovou validitu – tedy to, že se skutečně ptáme na správné otázky. Všechny položky následně prošly jazykovou korekturou a během tzv. „kognitivní pilotáže“ s několika málo rodiči jsme ověřili, že jsou dostatečně srozumitelné. Tím jsme zajišťovali tzv. validitu odpověďových procesů – tedy že rodiče odpovídají přesně na to, co chceme, a že nepochopili jednotlivé otázky špatně.
Položky poté prošly několika koly pilotního ověření s celkem 698 rodiči. Protože byl celý dotazník velmi dlouhý, pracovali jsme s různými verzemi. Žádný z rodičů tedy neodpovídal na všechny otázky, což zvyšovalo náročnost následující statistické analýzy. Tímto „sítem“ prošlo jen 302 položek, které postoupily do posledního kola ověřování. Zároveň jsme vyřadili celou jednu oblast logopedických obtíží, která nefungovala dostatečně dobře a nesplnila naše vysoké nároky na psychometrické parametry a kvalitu. V žádném případě jsme mezi naše klienty nechtěli pustit něco, s čím nejsme dostatečně spokojeni.
Samotné standardizační studie (hlavní ověřování dotazníku) se zúčastnilo 2346 rodičů, většina dat byla sebrána v rozmezí od srpna do října 2020 (ano, covidová pandemie do něj nepříjemným způsobem zasáhla). I v tomto případě nebylo možné zadat s ohledem na velké množství otázek dotazník celý. Byly připraveny různé varianty dotazníku s pomocí metod tzv. optimálního designu, abychom maximalizovali efektivitu následného statistického zpracování. Data byla statisticky zpracována v několika krocích. V prvních jsme použili různé metody pro další protřídění položek. Následně jsme sestavili několik modelů vycházející z teorie odpovědi na položku.
Skórování a administrace
Ve většině dotazníků a testů, se kterými se setká většina lidí, se prostě vezmou body za každou otázku či položku a sečtou se, čímž je vytvořen celkový skór. Tento postup, patřící do tzv. klasické testové teorie, je sice jednoduchý, má ale řadu nevýhod. Hlavní je ta, že při jakémkoli rozdělení testu (vynechání několika položek, nebo naopak výběru jiných otázek) přestává být možné skóry z různých verzí jednoduše navzájem srovnat. Primární důraz klasické testové teorie je tedy na celkové skóre.
Teorie odpovědi na položku (IRT; Item Response Theory) pracuje diametrálně odlišným způsobem. Jejím předpokladem je to, že existuje jeden či několik tzv. latentních rysů, které chceme měřit. V našem případě jde tedy o „míru depresivity“, nebo „míru dyskalkulických obtíží“. Čím vyšší míru tohoto rysu respondent má, s tím vyšší pravděpodobností odpoví na dotazníkovou otázku souhlasně. Různé modely v rámci IRT se liší právě matematickou rovnicí, která popisuje vztah latentního rysu a pravděpodobnosti té které odpovědi. Pokud známe parametry této rovnice (tedy vlastnosti otázek), lze na základě konkrétních odpovědí zpětně s určitou mírou chyby odhadnout míru latentního rysu (tedy např. jak moc je dané dítě depresivní). Tyto parametry položek jsme dopředu odhadli v rámci standardizační studie popsané výše.
Postup umožňuje navíc i tzv. počítačové adaptivní testování, které jsme v dotazníky ePsycholog využili i my. Po každé odpovědi, kterou respondent poskytne, je znovu a znovu odhadována tzv. „průběžná“ úroveň měřených latentních rysů. Na jejím základě je pak vybraná optimální následující otázka, která o rodiči (respektive dítěti) přinese co nejvíce informace. To proto, že každá otázka je vhodnější pro jiné rodiče/děti – některé otázky rozlišují respondenty s velmi nízkou a nízkou úrovní latentního rysu (tedy např. děti bez depresivních symptomů a s mírnými symptomy), jiná s vysokou (tedy například středně hlubokou a hlubokou depresi). Celý postup nám zároveň umožňuje mít různé otázky pro rodiče různě starých dětí, avšak vyhodnocovat je do jisté míry stejným způsobem v rámci jediného statistického modelu.
Díky tomu jsme schopni každému klientovi „namíchat“ optimální otázky a nezatěžovat jej takovými, na které s vysokou pravděpodobností odpoví souhlasně či nesouhlasně, a které nám nepřinesou mnoho informace. Pokud se na základě již zodpovězených otázek například zdá, že je posuzované dítě vysoce depresivní, neklademe rodiči otázky, které rozlišují mezi žádnou a mírnou depresí – ale naopak otázky, které se týkají středně silné a velmi silné deprese. Pokud však rodič odpoví vícekrát nesouhlasně, náš statistický model přepočítá všechny parametry a začne se opět ptát na mírné symptomy deprese. Žádný rodič proto nemusí odpovídat na více než 300 položek v našem dotazníku; často stačí méně než 50, abychom byli schopni poskytnout relevantní závěr. Někteří rodiče tak mohou mít pocit, že je dotazník velmi krátký. Nechceme však naše klienty zatěžovat více, než je nutné, jen aby měli pocit, že za své peníze dostali „rozsáhlý“ dotazník.
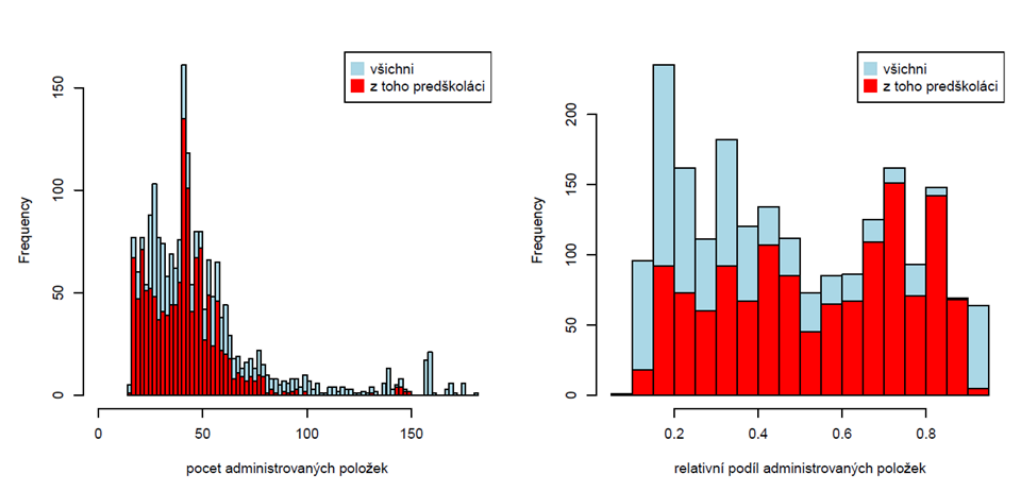
Počet zadaných otázek a míra zkrácení dotazníku oproti „plné verzi“ je patrná z následujícího obrázku. Vlevo je vidět rozložení celkového počtu otázek, který je nutné zodpovědět. Je patrné, že nejčastěji rodiče zodpoví necelých 50 otázek, a více než 150 otázek je nutných jen výjimečně (a to zejm. u školních dětí). Vpravo je pak znázorněno rozložení podílu otázek, který rodič musí zodpovědět z celkového počtu, který je v naší databázi k dispozici. Je patrné, že téměř nikdy nestačí méně než 20 % (0,2); občas je však nutné použít téměř všechny otázky, které máme k dispozici (hodnoty 0,8–1 na vodorovné ose).
Tvorba tohoto adaptivního mechanismu byla poměrně náročná. Přestože jsou jednotlivé statistické postupy dobře popsané v odborné literatuře, bylo nutné přetavit matematické rovnice do programového kódu napsaného na míru tak, aby dobře fungoval v prostředí online aplikace. Protože celý postup zahrnuje složité diferenciální rovnice bez analytického řešení, bylo potřeba využít služeb matematiků zaměřených na numerickou optimalizaci. Vyřešení všech obtíží spojených s vyhodnocováním dotazníku nám proto trvalo více než rok čistého času.
Vyhodnocení
Naším cílem bylo pro každou z oblastí poskytnout pravděpodobnost stanovení diagnózy odborníkem. S využitím skórů z našeho dotazníku jsme proto sestavili tzv. prediktivní model (tedy modelu, který se snaží předpovídat budoucí chování). Ten fungoval skvěle u ADHD, PAS a depresivně-úzkostných obtíží. V potížích se čtením, psaním a matematikou sice fungoval stále dobře, ale přímé stanovení pravděpodobnosti nebylo dostatečně spolehlivé. Podle nás je příčinou fakt, že diagnostika dyslexie, dysgrafie, a hlavně dyskalkulie je v České republice poměrně nahodilá. Záleží na mnoha faktorech, například zda se dítě dostane k odborníkovi, na okolnostech testování, na individuálních potřebách jednotlivých klientů apod. Proto u těchto oblastí používáme tzv. „normativní vyhodnocení“ – tedy srovnání míry obtíží s „normou“, tedy tím, jak odpovídají ostatní rodiče. Tímto postupem ostatně funguje naprostá většina psychodiagnostických metod. Naopak naše „kriteriální“ vyhodnocení, tedy přímé stanovení pravděpodobnosti, které používáme u ostatních oblastí, je poměrně unikátní.
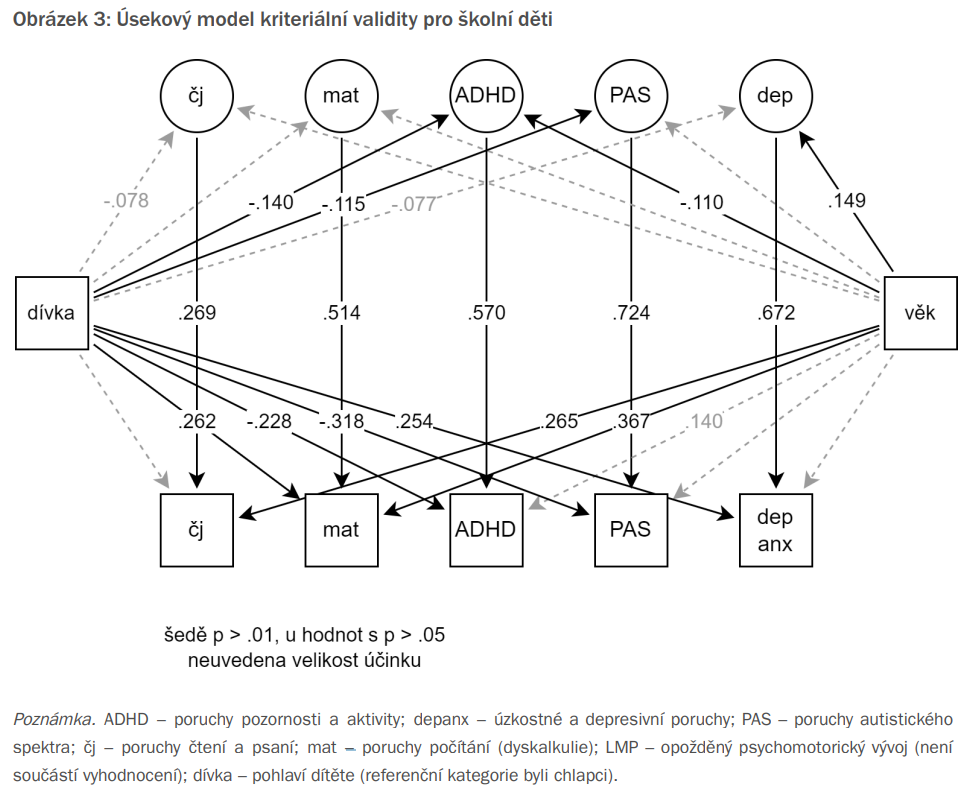
Ukázka tohoto prediktivního modelu pro školní děti je na následujícím obrázku. Ovály nahoře reprezentují skóry našeho screeningového dotazníku v jednotlivých oblastech. Čtverce dole jsou potom informace o stanovené diagnóze. Kromě toho v grafu figuruje i rozdíl mezi chlapci a dívkami a věk posuzovaných dětí. Čísla reprezentují standardizovanou těsnost prediktivního vztahu na škále od –1 do 1. Hodnoty –1 a 1 znamenají perfektní vztah (pro –1 „čím více, tím méně“, pro +1 pak „čím více, tím více“). Naopak 0 znamená žádný vztah. Je tedy patrné, že pohlaví dětí souvisí zejména s udělením diagnózy ADHD či depresivně-úzkostných obtíží: dívky mají méně často diagnózu ADHD, avšak jsou častěji diagnostikovány jako například depresivně úzkostné. Zároveň je vidět, že náš dotazník nejlépe predikuje míru autistických (PAS) a depresivních (dep) obtíží, v případě obtíží se čtením a psaním (čj) je těsnost vztahu mezi skóry a udělenou diagnózou o něco menší.
Po dokončení celé aplikace vývoj samozřejmě neskončil. Potřebovali jsme totiž vyzkoušet, jak dobře funguje v praxi. Několik měsíců proto probíhalo testování s reálnými uživateli, kterým jsme náš screening nabízeli zdarma. A i nyní, v ostrém provozu, stále sbíráme a vyhodnocujeme data. I z těchto důvodů každému uživateli naší služby posíláme dotazník s prosbou o zpětnou vazbu, která je pro nás velmi cenná.
Závěrem
Žádná psychodiagnostická metoda není dokonalá, a měření v psychologii je vždy zatíženo značnou mírou chyby. Psycholog je během vzdělání připravován k tomu, aby míru chyby dokázal správně vzít v potaz. Pro laika to může být obtížné, a proto se nejistotu spjatou s naším měřením snažíme zohlednit i ve zprávách, které rodičům poskytujeme. Na rozdíl od jiných (často méně kvalitních či dokonce podvodných) dotazníků, které jsou na českém i zahraničním trhu k dispozici, nikdy netvrdíme, že něco „přesně víme“. Náš (a žádný podobný) dotazník není schopen jednoznačně „odhalit“ potíže vašeho dítěte. Můžeme pouze nabídnout určité pravděpodobnosti, a pomoci vám tak při vašem rozhodování, zda je nezbytné vyhledat pomoc odborníka.
Pokud jste dočetli až sem, zdá se, že vás fungování naší diagnostické metody opravdu zajímá. V takovém případě se můžete podívat do našeho Technického manuálu , nebo se nás přímo zeptat na info@epsycholog.cz . Rádi vám jakékoli dotazy odpovíme.